
行政職員のためのデータ活用一歩前

0. 本記事について
免責と想定読者
本投稿は、浅見個人の意見や信念を多く含む"ポエム"です。必ずしも所属組織を代表する意見ではありません。
また、本記事の想定読者は、データ分析(データ活用)を担当する課に配属された行政職員です。特に専門職採用というわけでもなく、データ分析・モデリングの特別な教育を受けていない読者を想定しています。
あくまで行政職員をイメージしているため、民間企業では適切ではない事例も多いかと思います。ご了承ください。
データ活用の主語についても、あくまで「行政職員」を想定しています。「国民」を主語にしたデータ活用の課題(例えば、神Excel問題や煩雑な紙申請問題など)は本記事ではスコープ外としています。
なお、本記事では「政策」「施策」「事業」について、特に区別を設けず「政策」という言葉で統一しています。
要約
1. 最初の一歩
まずメトリクスを定義して、監視する習慣をつけましょう
ただ、監視するだけでなく、アクションプランも考えましょう
現状の把握、最初はこれだけでも十分だと思います
2. データ”分析”は必要か?
必要です。EBPM的な社会的要請に応える必要がある
ただし、期待値コントロールを忘れずに
3. 分析タスクの理念型
データ分析の理念型を以下の3つとして整理
個人的に好きな図書を紹介
(1) 政策分析
政策実施前に行う分析
(2) 効果検証
政策実施後に行う分析
(3) 機械学習タスク
サービス価値の創造や高度化を図るようなモデリングタスク
4. 誰が担うべきか
内製化が理想。ただし、専門人材の育成や組織には時間がかかる
無理のない範囲で少しずつ内製化を検討しましょう
外注であっても、最低限の知識がないと発注者責任を果たせません
5. 品質問題
仕事である以上、その分析結果の品質には責任を持たなければなりません
① 分析そのもののバグ
② 分析フローのバグ
特に②のバグは、第三者から指摘しにくい分野
相互レビュー体制を整えましょう
6. さいごに
公共政策は純粋工学ではありません
事実判断と価値判断の両方を適切に管理しましょう
1. 最初の一歩 : 大切なものはなんですか?
Data analysis starts with questions, not data or a technique
(データ分析はデータや手法ではなく、問いから始まる)
@ Google 非公式ブログ(邦訳は浅見)
「データがない」が問題なのか?
この手のプロジェクトが始める際に、「データの蓄積をまず頑張ろう」「全てのデータを奇麗にしよう」「どんな統計ツールを買えばいいのか」という議論になりがちです[1]。

しかし、これはやはり効率のよい検討順序ではありません。無計画なデータ収集や基盤・ツール整備は、高確率で出戻りが発生するか技術的負債として放置されます。このようなプロジェクトで蓄積されるのは、「データ」ではなく「現場の不満」かもしれません。
本当に足りないのは、「データ」ではなく「我々は何をすべきか」という問いではないでしょうか。この「問い」なくして、適切な基盤や収集すべきデータは特定できません。
大切な価値の定義から始めよう
あなたの部署/グループ、もしくはプロダクトで、守りたい/最適化したいメトリクス(指標)はなんなのか、まずはこれを考えることから始めてはいかがでしょうか?

このプロセスにおいて、複雑な統計学や機械学習、コンピューターサイエンスの知識は不要です。外部の専門家ではなく、業務/プロダクトをしっかり理解している現場の行政職員が考えましょう。
もちろん、無理に数百個も定義する必要はないと思います。一時的に頑張って、情報過剰なダッシュボードを作ったとしても、忙しい行政職員は、絶対に見なくなります。
本当に必要なメトリクスを定義し、それを定点観察(モニタリング)する仕組みをまず作りましょう。人間でいうところの健康診断に似ています。
加えて、そのメトリクスとどう向き合うか事前に決めておきましょう。
例えば、目標値/適正値の決めておく、また特定の警戒閾値を決めておき、閾値を超えた場合のアクションプランを設けておくなど、行動・対策方針を決めておくと良いでしょう。イメージとしては、以下の2つです。
保安系の部署における意思決定分析のイメージ
モニタリング:〇〇事故率を、月次で、都道府県別で確認する
アクションプラン:上記粒度で、前年同月のXX倍を超過したら、対策会議を設けることにする
不正検知プロダクトでのイメージ
モニタリング: 適合率(Precision); 再現率(Recall)を月次で確認
アクションプラン:Xヶ月連続で再現率が△△%を下回った場合、機械学習モデルをリプレイス
メトリクスを定義し、ただ綺麗なダッシュボードを作るだけではなく、モニタリングとアクションが有機的につながるような文化の醸成、仕組み作りが最初の一歩だと私は考えています[2]。

2. データ”分析”は必要か?
A team fails when they’re hired because “Hey, we have a lot of data, and, hey, you’re data scientists. You figure out what to do with that.” A team will fail if there’s not a clear focus.
(「我々は大量のデータを持っているよ、君たちはデータサイエンティストでしょ?このあと何をすべきか教えてよ」のような理由で採用されたチームは失敗する。明確な目的がないと、チームは失敗するのです。)
過大な期待と不明確な問い
上記までの取組(メトリクスを定義して、モニタリングする)だけで必要十分かどうかは良い問題です。一般論ですが、「データから何か示唆を得たい」というような素朴な(曖昧な?)願いに基づいて、データ利活用プロジェクトが組成されることも多い印象です。
以下のようなキャッチフレーズをどこかで聞いたことはないでしょうか[3]?
「おむつを買った人はビールを買う傾向がある」
メディアや講演などでよく語られ、データ分析・データマイニングという言葉を一躍有名にしたフレーズです。このような成功事例があることは否定しません。ただし、データを分析すれば、
今まで全く気づかなかったことがわかる
必ず驚くような示唆が得られる
と考えるのは危険です。
大抵の作業が「当たり前の再確認」作業であることが多く、過大な期待は幻滅を招くだけです。むしろ、「ちょっとデータを分析した程度で、驚くような事実が量産される組織」は非常に不健全な可能性すらあります。現場の声が届いていない証拠であり、データ分析を検討する前に、フィールドに足を運び、現場の声に耳を傾けるべきです。
一般論として、「分析はあくまで手段」「分析ニーズが本当にあるか」「分析課題は明確か」のような交通整理/期待値コントロールから始めることを強くお勧めします。
行政に必要な分析課題は”ある”
行政機関において、データ分析は必要でしょうか。
私は必要だと考えます。
財政が逼迫する我が国において、リソースの合理的な配分に対する国民的な関心は日々高まっています。所謂、EBPM(Evidence-based Policy Making: エビデンスに基づいた政策立案)などの標語がこれにあたります。
我々は国民に対して、政策の目的合理性及びその効果を説明する責任があり、そしてその立証方法は(残念ながら)単純なデータの監視、集計や可視化では不十分である可能性があります。我々は、(組織として、)もう一歩進んだ分析ノウハウを習得する必要があると考えています。

ただし、いきなり高度な分析に向かうのは制度的・人材的な課題をいくつも越えなければなりません。
ステップ論として、まずは、前章で確認したような組織文化の醸成に優先的に取り組むのも悪くないかと思います。

次の章以降では、もう一歩進んだ取組を目指す皆様に向けて、データ分析の理念型(分類)を整理した上で、その最低限把握しておいた方がよい観点をいくつか紹介します。
3. 分析タスクの理念型
以下の分類は、特に学術的なものではなく、浅見個人のイメージであることに注意してください。これ以上に細かくすることも可能ですが、最初はこの程度の粗い分類で理解すると楽だと思います。
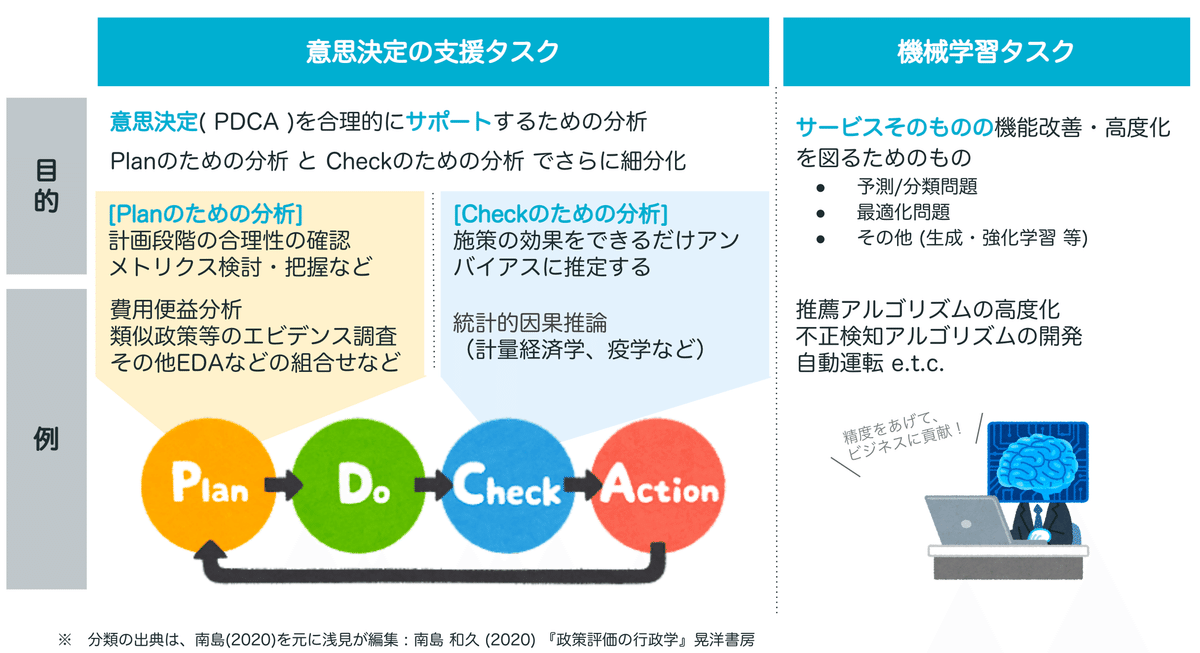
大きく分けると、人間の意思決定をサポートするための分析タスク か サービスそのものの機能改善・高度化を図るための分析(モデリング)タスクです。前者は、もう少し俗っぽく表現すれば、PDCAをサポートするための分析で、Planのための分析とCheckのための分析にさらに細分化できます[4]。
(狭義のEBPMは、この「Checkのための分析」に該当します。)
(1) Planのための分析
PDCAのPの部分、つまり政策実施前に行うべき分析作業です。「政策分析」と「効果検証の事前準備」の2つに分けて簡単にコメントします。
a. 政策分析
行政学系の教科書で政策分析(policy analysis)と呼ばれている分析群です(南島 2020)。非常に多岐にわたるため、政策の特性によって向き不向きが激しいのもこの分野です。

ただし、難しく考えすぎず(=高級な理論を期待するのではなく)、確認すべき「問い」を明確にして、それを丁寧に確認していくことが重要かと思います。
どのような「問い」を持つべきかについても、所属の組織や政策の特性にもより、一概には言えないのですが、浅見個人がよく利用する「問い」は以下の3つです。
a-1 : 政策介入の必要性
・介入が必要なほどメトリクスが毀損しているか:メトリクスの監視
・政府(地方自治体)が介入する必要があるか:市場の失敗の検証
a-2 : 政策介入の効果(及びコスト)の見積もり
・政策シミュレーション、産業連関分析
・費用便益分析
・類似政策が過去にあるのであれば、そのエビデンスの調査 等
a-3 : 政策オプションの”合理性”の検証
・我々の政策選択は”合理的”か(効用をより良く反映できているか)
(a-3)はやや抽象的なので補足します。ここでは、意思決定における分析フレームワークを想定しています。前提としては、「我々人間は(主観的)評価軸(効用順序)を適切に整理して、最適な政策オプションを選択することが苦手」であるというものです。(処方的)意思決定分析は、ある合理性の基準や公理を定義し、複雑な意思決定の問題について、系統的な検討プロセスを提示することで、意思決定者をサポートすることを目指します。
例えば、AHP(Analytic Hierarchy Process:階層化意思決定法)という言葉を耳にしたことはないでしょうか。一体比較法というアンケートを用いて価値基準及び政策オプションの優先順位を定量的に整理し、意思決定・合意形成を支援する本手法は、その簡便さから広く知られている意思決定分析の一つです(小笠原 2009)。

b. 効果検証の事前準備:代替メトリクスの研究
一番最初にメトリクスを定義するべきと主張しました。PDCAを適切に回すという観点で言えば、もう一歩踏み込むといいと思います。
普段モニタリングしている指標が、必ずしも効果検証にとって有益とは限りません。政策介入に対して感度が高く、できるだけ短期間で観察できて、また政策介入の粒度と適合したメトリクスを(複数)事前に開発することが望まれます。これをここでは代替メトリクス(Surrogate Metrics)といいます。
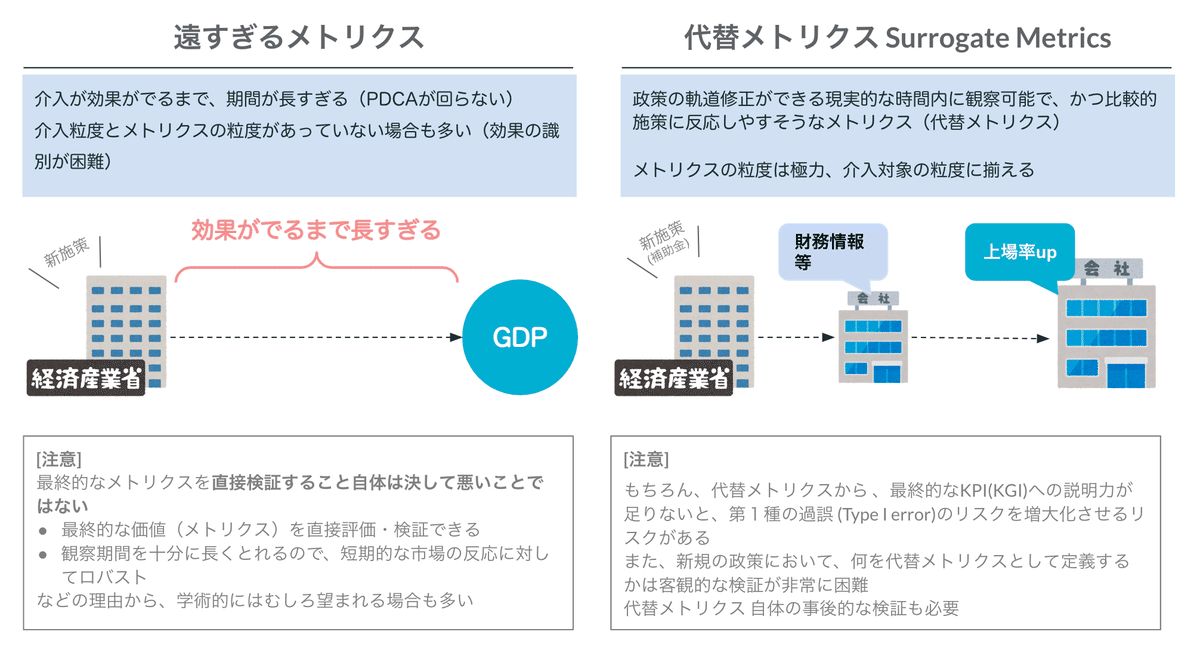
代替メトリクスを設置する第一の目的は、政策の軌道修正を現実的な時間内に行うためです[5]。行政職員であれば、ロジックモデル におけるアウトカムとインパクトの関係だと理解していただいても結構です。
10年後に「昔やったXX政策、効果が実はなかった」と判明しても、(分野にもよるとは思いますが、)その結果を用いて次の政策に活かすことは難しいかもしれません。
それよりは、1年後に「今やってるXX政策は、平均としては効果がないのかもしれない。しかし、△△業種において、かなり効果があるかもしれない」(効果の異質性の発見)ということが分かれば、次の年度で当該政策を軌道修正できるかもしれません。
政策実施前の段階で、この代替メトリクスを定義/開発しましょう。
過去に類似した政策があれば、適切な代替メトリクスをある程度客観的に設定することは可能かもしれませんが、ほとんどの場合、ドメイン知識やEDA(探索的データ分析)による仮説ベースでの設定になると思います。
大切なのは、代替メトリクス も多くの場合仮説であるということです。上記のロジックが成り立つのは、「あくまで代替メトリクスが最終的なメトリクス(KGI)に対して説明力(予測力)がある」という前提です。これは新規の政策であれば、客観的なデータで示すのは難しく、あくまでロジカルに説得するしかありません。
そして、仮説であるなら、やはり事後的な検証が必要です。政策自体の効果検証を忘れることはないとは思いますが、この代替メトリクスの選定の検証は忘れやすいので注意しましょう。
仮説-検証のプロセスの中で、代替メトリクスの最終的なメトリクス(KGI)に対して説明力(予測力)とその不確実性が明らかになってくれば、政策の代替メトリクスにおける目標値を設定しやすくなり、より確度の高いPDCAが回せるようになるはずです[6]。
[入門書 3冊]
① Ron Kohavi, Diane Tang,Ya Xu (2021)『A/Bテスト実践ガイド 真のデータドリブンへ至る信用できる実験とは』KADOKAWA.
本書は狭義のA/Bテスト(RCT)のHowTo本というより、メトリクスの決め方、システム的な手当て、そして組織文化等までを広範なテーマを扱う啓蒙本です。やや行政職員にとって過剰な部分はあるかもしれませんが、それでも示唆に富む書籍だと思います。
② 橋本 洋志, 牧野 浩二, 佐々木 智典(2022)『Python 意思決定の数理入門』オーム社.
上記で言及したAHPだけであれば、木下(2006)の方が丁寧ですが、せっかくであればオペレーションズ・リサーチ(OR)全体を学ぶといいと思います。武器(分析の切り口)は少ないより多い方が絶対にいいと思います。
③ 馬場真哉 (2021) 『意思決定分析と予測の活用 基礎理論からPython実装まで』講談社.
予測モデルの結果を意思決定にどうつなげるかというテーマの良書。それと同時に、意思決定分析のわかりやすい入門書になっています。
(2) Checkのための分析
PDCAのCの部分、つまり政策実施後に行うべき分析群です。一般に、効果検証やプログラム評価といわれているものになります。また、EBPMの一丁目一番地もこの分野になり、国民からの関心も非常に高い分野です。
以下では、効果検証のための手法(統計的因果推論)を学び、業務に活かすためのポイントを何点か紹介します。
a. 必ず教科書を読む
一番大切なポイントかと思います。因果推論タスクは、分析の"確からしさ"をデータ等で説得的に示すことは極めて難しい分野です。
対比として、機械学習の予測タスクを考えてみてください。予測タスクであれば、テスト用データセットに対する精度指標を示すことで当該モデルの妥当性を示すことはできます。

因果推論の場合、これはできません。機械学習的な言い方をすれば、Ground truth(正解)が未知なのです。分析の結果、「当該政策の効果が平均して+10%」だったとしても、その報告結果をどのように信じればいいのでしょうか。
解決策は、理論(と因果推論の思想)をしっかり学ぶこと以外ありません。計算自体はPythonやRのパッケージを利用すれば簡単に実行可能です。ただし、正しく使う、結果を外部に説明するためには、しっかりとした教科書・論文を読むしかありません。
昨今では、因果推論もブームになってきていますが、同時に「モデルの解釈可能性」、「XAI」や「因果探索」などの議論と混同して理解してしまう方もよく見かけます。そしてこれは、プロであるはずの分析ベンダーにおいても、例外ではありません。
国民からの注目度の高い分野でもあるため、外注するにしても、内製化するにしても、しっかりとした教科書を一度読んでおくことを強くお勧めします[7]。
b. 手法をより良く選択する:戦略(と限界)を知る
統計的因果推論は、複数の手法(作法)の総称です。実際には、個々の政策の性質をよく考慮のうえ、適切な手法を選択する必要があります。
分析の適切性は、採用手法における識別戦略( Identification strategies : 因果関係を識別するための戦略)の説得可能性に深く依存します[8]。
「識別(条件)」はやや馴染みがない言葉かもしれません。代表的なものは以下の3つです。

一つ一つの説明は教科書をご確認ください。この識別条件が全て満たされれば、基本的に政策の因果関係を推定することは可能です。ただし、実験(RCT)の場合を除き、この識別条件が成立していることは極めて稀です。
大抵の手法は本条件について緩和戦略(識別戦略)をとります。
Ignorability (無視可能性)を一例として:
- 交絡(共変量)で「条件付けた Ignorability 」で代替
- 閾値や操作変数を利用した「局所的な Ignorability」を期待
- あるいは「並行トレンド parallel trend」を仮定として置き換える 等
どの戦略が優れているかは、政策の性質や、アクセスできるデータの質に依存するのでケースバイケースです。全ての政策に通用する万能な手法はありません。
また、大切なのは、選択した識別戦略(手法)によって、推定した結果の性質も変わってきます。
例:
(1) 並行トレンド仮定を導入 :
介入群における平均因果効果 (ATT: Average Treatment Effect on the Treated )
(非介入群に同じ政策を施しても同じ結果になるかは不明)
(2) 局所的な Ignorabilityを仮定 :
局所平均因果効果(LATE: Local Average Treatment Effect)
(局所条件から離れた主体の因果効果は不明)
DIDやSC法、回帰モデルや操作変数など、色々な細かい手法はありますが、それぞれについて:
どのような(緩和)仮定を導入して、
その(緩和)仮定から得られた結果がどこまで一般化できるのか
を整理して理解すると良いかもしれません。
c. Ignorability (無視可能性)以外の識別条件も忘れない
Ignorability (無視可能性)については、多くの手法で主題的に扱われるため忘れる方はほとんどいません。しかし、その他の識別条件についても同様に注意が必要です。
特に現場でよく悩まされるのがSUTVA条件です(厳密には、3つ目のConsistency(一貫性)を内包している概念ですが[9]) 。我々の介入対象主体(企業、国民など)は相互に強く関連しているため、政策介入の効果が、非対象主体まで影響を与えてしまう可能性があります。

このような状況下では、正しく政策効果を識別することは困難であり、分析結果にバイアスが乗ってしまう可能性があります。
このような条件違反を検知・修正するためには、教科書的な知識と政策に対するドメイン知識の両方が必要になってきます。
d. 安易に手法間の優劣をつけない
手法間に無理やり順序関係を持ち込もうとするのはアンチパターンです。
手法の中には難易度が高いものもあり、それが”カッコイイ”ように見えるかもしれません。最近では、深層学習に基づく手法(Shalit et al. 2017, Johansson et al. 2016)なども提案されており、使ってみたくなる気持ちもわかります。

しかし、分析の適切性は手法の理論的難易度とは別問題ということを忘れないでください。シンプルな重回帰分析による調整で十分な事例も多く存在します。
e. 極度な因果推論潔癖症
因果推論を勉強すると、様々なバイアスの可能性に敏感になってきます。これは悪いことではありません。
「この回帰モデル、重要な〇〇共変量を調整していなけど、大丈夫か」や「この分析、並行トレンド仮定が本当に成り立っていえるの?」といった具体的な批判は歓迎すべきものです。それに応じるかたちで、より納得感のある結論に到達できることが期待できます。
しかし、一方で具体性のないバイアスへの不安は建設的な議論につながりません。分析結果に違和感がある際、「どの仮定について、なぜ不十分といえるか」を具体的に指摘するよう心がけましょう。

f. 政策の計画段階から効果検証は始まっている
狭義の分析作業(計算作業)は確かに、政策実施後に行いますが、広義の分析作業は政策実施前から始まっています。必要なデータの設計や執行フレームワークの工夫などがそれにあたります。このようなリサーチデザインは、政策が終わった後から始めるのはかなり無理があります[10]。

もちろん、理想論としては、政策実施前(検討段階)から、専門家をアサインできれば一番なのですが、それが難しい場合は、全体研修等で対応しましょう。
全体研修でプロの分析官を育てるのはかなり難しいと思いますが、まずはリサーチデザインを適切に設計できるレベルをスコープとした研修は十分可能と考えています。
g. 政策を選ぶ:意思決定につながる政策から優先的に関与する
効果検証はPDCAのC(Check)の部分です。次のA(Action)に繋げられる政策を選ぶのがまずは良いのではないでしょうか。継続的に行う政策であれば、効果の有無や異質性に従って、次年度以降の政策立案に影響を与えることができます。
もちろん、単発の政策であっても、事後的な検証は必要です。これは国民への説明責任という観点です。両方大事なのですが、職員のリソースも限られているので、できるだけ軌道修正できる政策から優先的に対応することをお勧めします[11]。
h. 基本的に政策は思い通りにいかない
効果検証は、その性質上、決して低くない確率で不都合な真実、つまり「政策の失敗」に遭遇します。以下は、KDD2009のワークショップにおけるMicrosoft社での効果検証の成功実績です。
Now that we have run many experiments, we can report that Microsoft is no different. Evaluating well-designed and executed experiments that were designed to improve a key metric, only about one-third were successful at improving the key metric!
(多くの効果検証を実施した今だからこそ言える。Microsoftも例外ではない。よく設計され、実行された施策を評価したところ、その重要な指標の改善に成功したのはたった3分の1程度だったのです)
(邦訳は浅見)
もちろん、業態の全く異なるものですので、行政における政策成功率が33%だというつもりはありません。ただし、Microsoft社のようなデータドリブンなテック企業ですら、この成功率だということは覚えておいてください。
最悪のアンチパターンは以下です。

政策の失敗の発見は、分析者及び政策立案者に必要以上の負荷をかける可能性があります。いくら計量経済学や統計学を必死で勉強しても、それを活かす組織(組織文化)を醸成しないことには、持続可能なEBPMは難しいかと思います。
統計的因果推論の”方法”については、教科書や論文を読むことで習得できますが、組織における”活かし方”については解がありません。査定権限のある部署や幹部を巻き込んで、組織的な議論を繰り返すしか道はないと考えています。
効果検証の一番の難しさは、効果検証の組織論的なインセンティブの設計ではないでしょうか。この意味で、効果検証業務で真に読まなければいけない教科書は経営学や組織論なのかもしれません。。。(著者はこの分野に疎いのですが)

[入門書]
① Ron Kohavi, Diane Tang,Ya Xu (2021)『A/Bテスト実践ガイド 真のデータドリブンへ至る信用できる実験とは』KADOKAWA.
2度目の紹介です。因果推論を勉強すると、ignorability (無視可能性, exchangeabilityとも)条件のみに注意が偏りがちになる。本書は、効果検証におけるアンチパターンを様々な角度で紹介しているので、まずは本書から入門することをお勧めします。
② KRSKスライド(2019)「因果推論のための3ステップ入門」
細かい理論を追いかける前に、まずは全体像を把握するといいと思います。KRSK氏はブログでも、有益な情報を発信しているのでお勧めです。
③ Brady Neal (2020) "Introduction to Causal Inference from a Machine Learning Perspective" 講義資料+公開テキスト
個人的にはNealの教科書及び講義資料が好きです。各手法の記載は入門書的性質上限定的ですが、部分識別、因果探索、感度分析や機械学習系の手法など、カバー範囲は非常に充実しています。各章に講義スライドと動画も用意されており職場での輪読会でも使いやすい教材だと思います。
日本語で勉強したい方は安井(2020)や高橋(2022)などで入門してもいいかもしれません[12]。
(3) 非EBPMタスク:機械学習タスク
上記の(1)と(2)はあくまで、人間の意思決定をサポートするための分析でしたが、本タスク(3)は分析やモデリングそのものが、サービスの高度化や付加価値の創造を志向するケースが多い分野です。EBPMの観点から言えば、優先順位は劣後しますが、一部の官公庁では進んだ取組もあるようなので、簡単に取り上げようと思います。
a. 最初に検討すべきこと
Before Machine Learning Rule (機械学習ルールを導入する前に)
#1: Don’t be afraid to launch a product without machine learning.
(機械学習を使わないことを恐れない)
(邦訳は浅見)
これはGoogleのリサーチエンジニア、Martin Zinkevich さんの機械学習プロダクトベストプラクティスからの引用です。やや古いものですが、この原則は今でも変わっていないと思っています。
機械学習の開発は基本的に高コストでかつ、本当に自分たちが要求する精度に達成できるか事前に見積もることは困難です 。機械学習モデルをいきなり作るのではなく、ルールベースで解決できないか検討しましょう。
特に「AI」や「Deep Learning」など、”かっこいい”単語が頻出する分野であるため、なんとなくプロジェクトが始まってしまうケースも多い領域です。手段の目的化や誤用がないか確認してみましょう[13]。
b. メトリクスを設計・実装する
Before Machine Learning Rule (機械学習ルールを導入する前に)
#2: First, design and implement metrics.
(まずメトリクスを設計・実装する)
(邦訳は浅見)
また、具体的な手法(ルールベースを含む)の検討前に、メトリクスを設計し、実装・モニタリングしましょう。この文脈において、メトリクスとは以下の2つを想定しています。
モデルの精度指標
実務(プロダクト)メリットに関する指標
前者は、純粋に当該モデルの完成度を示す指標です。最適な精度指標は、外注したベンダーには原理的にわかりません。現状の問題意識や、当該ルール(機械学習)の運用フローに応じて、適切なメトリクスを設計する必要があるからです。
例えば、不正申請を検知する機械学習システムを構築する場合、システム判定の正確性を優先するのか、不正の見逃しを最小化したいのかによって、見るべき精度指標は変わってきます。

やや専門的な内容になるかもしれませんが、モデルの精度指標は発注者側も勉強しておいた方が良いと思います。
前者は狭義のモデルに対する指標ですが、後者に関しては、実務メリットに対する指標であり、本来の目的はこれを最大化することです。
前者と後者の関数(関係)について、仮説ベースでもよいので、議論しておきましょう。例えば、今検討している機械学習プロジェクトは以下の①〜④のうち、どれに近いと考えられるでしょうか?

① 一定型プロジェクト:これはどんなにモデルが高度になっていっても、実務上のメリットが向上しないパターンです。機械学習(手段)が目的化しているプロジェクトにありがちなアンチパターンです。
② 後期爆発型プロジェクト:モデルの精度が一定以上超過してから初めてご利益が発生するパターンです。注意しなければいけないのは、一定以上の精度に達成できなければ本プロジェクトは無価値になるリスクです。プロジェクトのアセスメントを徹底し、場合によっては、達成可能な事前課題を切り出しながら無理のないプロジェクトに設計しましょう。(例:いきなり自動運転の開発は難しいので、ブレーキ補助システムを開発する 等)
③ シグモイド型プロジェクト:モデルの精度ご利益が逓減していくパターンのプロジェクトです。このようなプロジェクトに、複雑なモデルの導入は必要ない可能性があります。運用の容易さや可読性も考慮しつつ、ご利益とコストに見合った合理的なモデルを考えましょう。
④ 線形型プロジェクト:これが理想的なプロジェクトです。モデルを高度化すれば、実務ご利益もその分発展するパターンです。このようなプロジェクトが本当にあるなら、外注などせずに機械学習エンジニアを内製化させましょう。
c. モデルを運用する覚悟
機械学習プロジェクトは「作って終わり」「外注して終わり」ではありません。機械学習モデルは"生き物"です。(完全な自然現象が対象な場合を除いて)モデルにも賞味期限があると思ってください。
データの仕様が変わってしまった
データそのもの分布が(モデル構築時から)変化してしまった
精度指標の優先順位が変わった
など、諸々の状況変化に対応しなければなりません。必ず精度指標をモニタリングし、必要に応じてモデルの再構築などを検討しなければなりません。

"Machine Learning Design Patterns" O’Reilly.
仮に機械学習プロジェクトを外注する場合、モデルの納品時の精度だけを気にするのではなく、自組織の運用体制の検討を同時に考えなければなりません。
[入門書]
① 有賀 康顕, 中山 心太, 西林 孝 (2021) 『仕事ではじめる機械学習 第2版』O'Reilly Japan.
機械学習そのものの教科書ではなく、「(機械学習に関連した)仕事の仕方」が丁寧に説明されています。”機械学習を使わない選択肢”という視点も大切にしており、最初の一冊としてお薦めです。
② 石川冬樹, 丸山宏・編著 柿沼太一, 竹内広宜, 土橋昌, 中川裕志, 原聡, 堀内新吾, 鷲崎弘宜 (2022)『機械学習工学』講談社.
機械学習に関連する運用、倫理、デザインパターン、品質管理など、狭義の理論以外の内容を網羅的に解説・紹介する名著です。章によって難易度は異なりますが、発注者側も是非読んで欲しい一冊です。
③ 高村 大也 (2010) 『言語処理のための機械学習入門』コロナ社.
機械学習そのものの理論も少ししっかり勉強したいという方は、本書から始めてみてはいかがでしょうか。自然言語処理シリーズですが、一般的な機械学習においても良い入門書になっています。余裕があれば、須山(2017)とセットで読むと、さらにその後の勉強がスムーズになると思います。
4. 誰が担うべきか
上記までで紹介した分析やモデリングを誰が担うべきかは、良い問題かもしれません。
外注を考えている方へ
行政組織の場合、人事制度上の制約から専門人材を確保することは確かに難しいかもしれません。短期的には外部専門人材を頼るのも悪い選択肢ではないと思います。
ただし、分析・モデリングを外注する場合であったとしても、もちろん発注者責任は残ります。リサーチ課題の整理やデータの設計や分析結果の評価など、発注者側にもある程度の知識が必要になります。
特に、継続的なメンテナンスが必要になるような機械学習タスクの場合、当該システムを自分たちでメンテナンスする体力があるかどうか意識する必要があると思います。
内製化を試みる方へ
素晴らしい試みだと思います。外注の調整・コミュニケーションコストや分析の一貫性、ナレッジの蓄積という観点から、最終的には内製化していくのが正解だと思います。
一方で気をつけなければならないのは、その品質管理です。データサイエンス領域には個人ブログや勉強会のスライド共有等の文化が根付いており、少し検索するとすぐに面白い情報にアクセスできます。これは素晴らしい文化だと思うのですが、仕事で使うとなると、最終的には教科書・そして関連する論文を読めるレベルの能力が必要です。
昨今では、R言語やPython等のパッケージや、ローコードツールの拡張機能の進化により、非エンジニアであってもモデルを作るだけであれば比較的容易にアウトプットがだせる時代になってきました。だからこそ、「やってみた系」の(理論的な裏付けが乏しい)分析・モデルが仕事で使われるリスクが高まっています。
もし内製化するのであれば、専門組織を組成し、相互レビュー体制の構築が必要です。組織的な体制が整わないうちは、外注ベンダーや外部有識者の方と共同しながら、無理のない範囲で取り組みましょう。
5. 内製化する際の品質問題
誤った分析から”正しい”意思決定を行うことは不可能です。分析・モデリングを業務として担当するということは、程度の差はありますが、その品質に責任を持たなければなりません。
本章では品質保証の議論を少しだけ紹介いたします。
2つのリスク
考えなくてはいけないバグ(リスク)は粗く分けると以下の2つです。
① 分析そのもののバグ
これはタイトルの通りです。統計学や機械学習、計量経済学に関する教科書的な知識の不足等に起因するリスク(バグ)です。
② 分析フローのバグ
①が完璧だったとしても、データのパイプラインにバグが残っていたり、分析の再現性が保てないような実行環境であったりと、エンジニアリング的な不備に起因するリスク(バグ)です。
この2つのリスクで、どちらが深刻かと決めるのは難しいですが、少なくとも②のバグは第三者から見えにくいという点で厄介です[14]。

②のリスクは、分析の内容やデータの種類によって、その難易度は異なりますが、例えば機械学習を実運用するために必要とされるシステムコンポーネントとしては下図(Sculley et al. 2015)が有名です。モデル(分析)のコアの部分は中央の小さい四角("ML Code")となっています。

もちろん、この論文は、モデル以外のシステムをやや大袈裟に紹介しているようにも思えますし、政策分析のようなアドホックな分析において、ここまでのシステム的な手当ては必ずしも必要ではないとも思います。
しかし、狭義の分析結果/モデル開発だけ専念すればよいという考えも非現実的であることは明らかです。
理想的にはエンジニア(データエンジニア 等)と共同のチームを作れるとよいかもしれませんが、データ利活用初期段階でこのようなチームを組成することはできません。

現実的な対応方針を以下で少し考えていきましょう。結論から言うと、銀の弾などはなく、まずは分析専門職の意識改革から着手するしかないと考えています。
箱モノ・ツールで解決?
上記でやや脅すようなことを書いたのですが、テック企業のようなモダンな技術スタックを無理に輸入する必要はありません。
むしろ、現場の分析専門職がコントロールできない箱モノを無理に外注で構築したとしも、高確率で誰も使わなくなります。

最初は分析専門職がコントロール可能でかつ安価な環境があればまずは良いと思います。下記のようなスクリプト言語での実行環境が整っていれば初期としては十分だと考えています。
初期の分析チームの環境例:
・データ加工及び分析としてのスクリプト言語実行環境(Python / R 等)
・SQL環境
・git環境(あれば便利)
意識改革が第一歩:脱”一人親方”分析
(ソフトウェア開発と異なり)分析業務は、一人で完結してしまうケースが少なくありません。その関係から、どうしても”一人親方”的な開発・分析スタイルを好む分析専門職が多い印象です。(著者自身もまだまだ未熟です)
そして、当たり前ですが、”一人親方”スタイルは、チームとして品質を担保することを困難にします。高価なツールを購入する前に、まずは分析メンバーの意識改革から少しずつ始めていきましょう。
具体的なアクションとしては、チームメンバー内で、以下のようなルール設定を議論してみましょう。
ルール (例):
・開発・分析ドキュメント(wiki)を必ず残すようにする
・リーダブルなコードをかく
・チームで定義した命名規則を守る
・できるだけ一般的なエンジニアが読める言語(PythonやSQL)で開発する
・テストをできるだけ書く
・Branch protection ruleを決めておく(git) など
あくまで上記は一例です。チームメンバーの能力や関心に従って無理なく開発や分析ができるルールに留めておく必要があると思います。
大切なのはメンバー間で成果物の検証を容易にする仕組みづくりです。そしてそれは、ツール等の購入で解決するものではなく、チーム全体のエンジニア的な文化の醸成が第一歩だと考えています。
[入門書]
① Dustin Boswell, Trevor Foucher (2012)『リーダブルコード』O'Reilly Japan.
自分のことを棚に上げて恐縮ですが、エンジニア(第三者)にレビューしてもらうための最低限のエチケットが濃縮されている一冊です。実験的なスパゲッティーコードは誰もレビューしてくれません。
一度に全てを身につけることはできないのですが、私も、(エンジニアに怒られながら)定期的に本書を読み返すようにしています。
② ゆずたそ,渡部徹太郎,伊藤徹郎(2021)『実践的データ基盤への処方箋』技術評論社.
データマネジメント/データ分析基盤が欲しくなってきたら最初に読むべき本。大きな考え方だけでなく、組織論的な話も豊富で、非エンジニアの方にも読みやすい。
③ Breck, E., Cai, S., Nielsen, E., Salib, M., & Sculley, D. (2017). The ML test score: A rubric for ML production readiness and technical debt reduction. In 2017 IEEE International Conference on Big Data (Big Data) (pp. 1123-1132). IEEE.
日本語にすると「ML(機械学習)テストスコア : ML生産準備と技術的負債削減のための行動規範」という論文です。機械学習に特化していますが、Googleにおけるシステム導入から得られた多くの事例や教訓が紹介されています。
6. さいごに : 公共政策は純粋工学ではない
認識と価値判断とを区別する能力、事実の真理を直視する科学の義務と、自分自身の理想を擁護する実践的義務とを(双方を区別し、緊張関係に置きながら、ともに)果たすこと、これこそ、われわれがいよいよ十分に習熟したいと欲することである。
統計学や機械学習、もう少し広げて経済学などの工学的知は、合理的な意思決定を支える上で今や必要不可欠なコンポーネントです。しかし、意識すべきなのは、これらの知が教えてくれるのは、基本的に社会が「どうあるのか」という事実命題(〜である)への問いのみだということです。
意思決定において、もう一つ重要な知は、当為命題(〜すべき)、すなわち「我々はどうあるべきか、何を優先すべきか」という問いです。
工学的な知によって明かされる事実命題が、必ずしも”倫理的”であるわけではありません。時として、”差別的”・”優生学的”な結果が顕になることも想定されます。
例えば、D.C.Rowは生物学的な犯罪学というある種のタブーに挑戦した書籍を発表しています(Row 2002=2009)。歴史的教養やリーガルマインドを持った"良識ある"大人であれば、これを危険と感じるかもしれません。例え、特定の生物学的・遺伝的な犯罪傾向が判明したとしても、それをダイレクトに政策につなげる(例:特定の遺伝的マーカーを持ったものを隔離する!)ことは許されません。事実判断「〜である」から価値判断「〜べき」への飛躍、これを一般に自然主義的誤謬といいます。
その一方で、Rowのような研究内容自体を、誤りであると「思い込む」態度も同時に危険です。「非倫理的なことは間違っているはず」という認知バイアス、つまり、価値判断「〜べき」から事実判断「〜である」を導出してしまう態度も、道徳主義的誤謬として敬遠されるべき態度です。価値判断の妥当性の基準を「事実の有無」に委ねているという点で、結果として脆弱な主張になってしまいます[15]。

事実判断と価値判断を明確に分離して整理しましょう[16]。そして、公共政策を担う我々は後者についても適切に意識・管理する必要があります。時に価値判断の基準は、ファクトの如何を問わず丁寧に練り上げる必要があります。人文科学や法学の知は、きっとこの意味で”役に立つ”と私は考えています。
価値は行為の結果を評価するための(つまり実際には、優先するための)特殊な視点を示すことによって、結果に関係する。評価視点の一般化が意味しているのは、それが個々の結果の実際の出現とは無関係に「妥当」し続けるということである。したがって価値とは抗事実的(kontrafakisch)に安定化された予期である。対応する結果が目下のところ生じていなくても、あるいはそもそもまったく出現しない場合でも、公然と価値を標榜しうるのだ。

標語として、EBPM(Evidence-based Policy Making:エビデンスに基づいた政策立案)を掲げるより、EIPM(Evidence-Informed Policy Making:エビデンスを踏まえた政策立案)の方がその思想を適切に表しているのかもしれません(加納, 林, 岸本 2020)。
公共政策は工学的な知を用いて完全に自動化することはできないし、そうするべきではありません。
長文の投稿、失礼しました。行政機関におけるデータ利活用のあり方について、少しでも参考になる部分があれば幸いです。引き続き、よろしくお願いいたします。
著者:浅見 正洋 (大臣官房DX室)
注釈
[1] 「データがない」という言葉は注意して解釈しましょう。
私は、以下の三類型で整理しています。どの場合も確かに「データがない」のですが、それぞれ原因が異なるので、対応策も変わってきます。
[データがない三類型]
a. 本当に欲しいデータがない(物理的・法的制約)
b. 必要なデータを職員が特定できない(分析目的と手法理解度が不足するもの)
c. 前処理スキルがなくて捌けない(リテラシーの話)
[2] 俗っぽい言い方で恐縮ですが、これがしっかりできてれば、それだけでも「データ駆動(Data Driven)」な行政活動ができていると主張してもいいと思います。
[3] このフレーズは1992年の『ウォール・ストリート・ジャーナル』に「Supercomputers Manage Holiday Stock( スーパー・コンピュータが管理するクリスマス休暇の在庫)」なる記事が発祥とされています。詳細はteradata japanブログ「データマイニング ― 確率で考る」 をご参照ください。
[4] 南島(2020 p.62)では、「政策分析型(policy analysis)」、「プログラム評価型 (program evaluation)」、「業績測定型 (performance measurement)」の三類型で整理しています。業績測定については、政策実施状況の把握を主眼としたものであり、予算執行状況のモニタリングなどがそれに当たります。本記事では割愛しますが、業績測定とプログム評価(効果検証)は質的にも異なる概念であることに注意してください。
業績測定:意図した通り政策が実行できているか確認する営み
プログラム評価:当該政策の効果があったか確認する営み
[5] 他にも、政策実施前にメトリクスを開示することで、"後出しジャンケン"で都合の良いメトリクスを選ばせて政策評価をさせない等の利益もあります。
[6] 代替メトリクスのより詳細な適用例は Linkedinの論文(Duan,W. et al. 2021)等をご参照ください。
[7] 例えば、ロジックがシンプルで、現場からも人気があるDID(Difference In Differences : 差分の差分)法ですらも、単純ではありません。本手法においても、最近盛んに方法論が再考されています。詳細については、Roth, et al. (2022) 等をご確認ください。
[8] 因果推論のフローチャートとしては、下図をご参照ください。

[9] Imbens & Rubin (2015)では、本記事3つ目の識別条件のconsistencyもSTUVAに含めている。本記事では分かりやすさを優先し、4つ目として整理した。
[10] たとえば、Randomized-encouragement design (Gelman & Hill 2007 p.216)など、政策実施段階で意図的に操作変数を仕込んでおくことで、検証段階の分析の幅を広げることができます。
[11] なんでもかんでも因果推論で解決しようとすることもアンチパターンです。あくまで、統計的因果推論は、政策の効果に不確実性を伴う場合に要請されている分析ご作法であり、単純な技術調査・実証事業についても、同じフレームワークをあてはめるのは無理があります。あくまで、当該予算事業の目的を定義し、その目的を素直に検証しましょう。
[12] より本格的な教科書探しについては、黒川先生のHP「因果推論のための計量経済学」や宗先生のHP「因果推論の道具箱」などを活用してみましょう。
[13] 稀にですが、EBPMの文脈で機械学習、Deep Learning等の単語を持ち出してくる方がいるので注意が必要です。機械学習のモデルが”解釈可能である”ということと、効果検証で要求されるような識別戦略を設計したうえでの因果効果の推定とは別物であると考えた方が無難です。最近では、高次元共変量(画像や文章などを含む)を調整するために、推定方法として機械学習を採用するような因果推論のフレームワークも複数提案されていますが(Chernozhukov et al. 2018 等)、まずは(2)の入門資料をしっかり読むことから始めた方がいいと思います。
[14] もちろんこれは完璧に分けられません。例えば、欠損値の処理や異常値への対応などは、純粋なエンジニアリングの問題ではなく分析の理論と密接な問題群です。
[15] より科学が発展した近い将来、仮により精緻な生物学的犯罪リスクが明らかになったと想像してください。道徳主義的誤謬の説得力は益々弱くなります。結果として大切な価値は守れません。いずれにしても、事実と価値は分離しなければなりません。「自然なものが善い」わけでも、「善いものが自然」なわけでもないのです。
[16] これは確かに論争的なテーマかもしれません。このような「ヒュームの法則」、ムーア「自然主義的誤謬 naturalistic fallacy」やウェーバー「価値自由 Wertfreiheit」は公務員試験の教養試験に出題されるくらいメジャーな概念ではありますが、少なくとも私が学生の頃は、哲学者・社会学者から格好の標的だったようにも思います。
「観察の理論負荷性」や「価値の被拘束性」テーゼ、「行為の事後決定性」仮説など、”事実は価値判断を常に含む”というような主張は、決して珍しくない主張でした。
事実とは、それを信じることが合理的であるような何かのことであり、あるいはより正確には、事実(ないし真なる言明)という観念は、それを信じることが合理的であるような言明という概念の理想化なのである。
私の立場は、このような立場とは距離を取り、ある意味ナイーブに事実命題と価値命題を分離することに意義を感じています。理由は以下の2つです。
1つ目、主張の有用性に対する疑義
まず当然のことながら、「価値の被拘束性」のような主張は、相対主義的な袋小路に陥るリスクが非常に高く、採用するには非常に高コストな思想と感じています。実証研究におけるこれらの批判・論争は、ウールガーとポーラッチによって提起された「存在論的な概念区分のごまかし(Ontological Gerlymandering)」批判・論争 (Woolgar & Pawluch 1985)をご参照ください。
また、彼らが主張する具体的な「事実の恣意性」については、十分に実証研究の文脈においても批判可能なものが多く、事実と価値の境界をわざわざ相対化するまでの利益を感じません。
2つ目、論証への疑義
確かに、ある種の事実判断に価値判断(文化や事前知識)が介在してしまうことはありえます(「虹の色が7色ではない国がある」説 等)。しかし、そのような境界事例を梃子(テコ)として、事実判断と価値判断は分離できないと主張するのは、滑り坂論法的で非常に弱い論証方式と感じます。
滑り坂論法(slippery slope) 或いは、連鎖法(sorites):
「いくつかのaがFであり、FであるaとFででないaとの間に原理的な区別がないなら、すべてのaはFである」という形式の論証法のこと
もちろん、私はメタ倫理学の専門ではありません。あくまで、上記は個人的な意思表明程度の内容です。反対に、道徳的実在論と功利主義の立場から、ヒュームやムーアから距離をとる方法として安藤(2007)なども示唆に富みますので、興味のある方はご確認ください。
参考文献 (紹介済み文献以外)
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., ... & Dennison, D. (2015). Hidden technical debt in machine learning systems. Advances in neural information processing systems, 28.
南島 和久 (2020) 『政策評価の行政学』晃洋書房.
秋吉 貴雄 (2017) 『入門 公共政策学』中公新書.
Duan, W., Ba, S., & Zhang, C. (2021). Online Experimentation with Surrogate Metrics: Guidelines and a Case Study. WSDM 2021: 193-201.
木下 栄蔵 (2006)『よくわかるAHP 孫子の兵法の戦略モデル』オーム社.
小笠原 春菜 (2009). 「Analytic Hierarchy Process とは何か - Capability Approach 研究の一方法として」千葉大学人文社会科学研究 19 134-157.
Imbens, G. W., & Rubin, D. B. (2015). Causal inference in statistics, social, and biomedical sciences. Cambridge University Press.
Roth, J., Sant'Anna, P. H., Bilinski, A., & Poe, J. (2022). What's Trending in Difference-in-Differences? A Synthesis of the Recent Econometrics Literature. arXiv preprint arXiv:2201.01194.
Shalit, U., Johansson, F. D., & Sontag, D. (2017). Estimating individual treatment effect: generalization bounds and algorithms. In International Conference on Machine Learning (pp. 3076-3085). PMLR.
Johansson, F., Shalit, U., & Sontag, D. (2016). Learning representations for counterfactual inference. In International conference on machine learning (pp. 3020-3029). PMLR.
Gelman, A. & Hill, J. (2007) "Data Analysis Using Regression and Multilevel/Hierarchical Models". Cambridge University Press.
Neal, B. (2020). Introduction to Causal Inference, 講義資料.
Cinelli, C. & Hazlett, C. (2020). Making Sense of Sensitivity: Extending Omitted Variable Bias. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(1),39–67.
Kohavi, Ronny, et al. (2009). Online experimentation at Microsoft. Data Mining Case Studies, 11(2009), 39.
安井 翔太 (2020) 『効果検証入門 正しい比較のための因果推論/計量経済学の基礎』技術評論社.
高橋 将宜 (2022) 『統計的因果推論の理論と実装』共立出版.
Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., & Robins, J. (2018). Double/debiased machine learning for treatment and structural parameters. The Econometrics Journal.
須山敦志 (2017) 『ベイズ推論による機械学習入門』 講談社.
Woolgar, S. & Pawluch, D. (1985). Ontological Gerrymandering : The Anatomy of Social Problems Explanations. Social Problems.32(3):214-227.
Hilary Whitehall Putnam. (1981=1994)『理性・真理・歴史 : 内在的実在論の展開』野本和幸, 中川大, 三上勝生, 金子洋之訳, 法政大学出版局.
Fordor, J. & Lepore, E. (1992=1997)『意味の全体論』柴田正良 訳, 産業図書.
Max Weber (1904=1998)『社会科学と社会政策にかかわる認識の「客観性」』富永祐治 折原浩 立野保 訳, 岩波文庫.
David C. Row. (2002=2009)『犯罪の生物学 遺伝・進化・環境・倫理』津富 宏 訳, 北大路書房.
桜井 芳生, 赤川 学, 尾上 正人(編) (2021)『遺伝子社会学の試み 社会学的生物学嫌いを超えて』日本評論社.
Niklas Luhmann(1968=1990)『目的概念とシステム合理性』馬場靖雄・上村隆広 訳, 勁草書房.
安藤 馨 (2007)『統治と功利 功利主義的リベラリズムの擁護』勁草書房.
加納 寛之, 林 岳彦, 岸本 充生(2020)「EBPMからEIPMへ 環境政策におけるエビデンスの総合的評価の必要性」環境経済・政策研究13 巻 (2020) 1 号.